Machine Learning für Einsteiger
Machine Learning ist in aller Munde. Das Interesse an dieser Technologie hat sich in den letzten drei Jahren bei Google Trends um fast die Hälfte gesteigert und befindet sich mittlerweile sogar auf Platz 3 der wichtigsten IT Themen. Das wirkt sich auch auf die Finanzen aus: In Deutschland wurde 2019 220,6 Mrd € Umsatz direkt oder indirekt durch Machine Learning generiert und mehr als die Hälfte der deutschen Unternehmen setzen mindestens eine ML-Anwendung ein.
Bei einem solchen Trend kann es leicht passieren, die Basics aus dem Auge zu verlieren. Hier wollen wir helfen und Einblicke liefern: Was ist Machine Learning, wie funktioniert es, welche Arten von Algorithmen gibt es und wie sieht es mit dem Datenschutz aus? Wir wollen euch die lange Suche im Internet ersparen und auch Nicht-Technikern oder Einsteigern die grundsätzlichen Merkmale von Machine Learning darlegen:
Was ist Machine Learning und wie funktioniert dieser Teilbereich der KI?
Machine Learning ist, wie man dem Titel schon entnehmen kann, ein Teilbereich der künstlichen Intelligenz und meint den Erwerb von neuem Wissen durch ein künstliches System. Einfach erklärt, generiert der Computer Wissen aus Erfahrungen und findet eigenständig Lösungen für neue und bekannte Probleme.
Die Funktionsweise des Machine Learnings orientiert sich am menschlichen Lernen. Der Entwickler ist hier sozusagen der „Lehrer“ und trainiert den Algorithmus. Durch Trainings- und Beispieldaten kann der Algorithmus Muster und Zusammenhänge erkennen und somit aus Daten lernen. Ziel des Machine Learnings ist es, Daten intelligent miteinander zu verknüpfen, Zusammenhänge zu erkennen, Rückschlüsse zu ziehen und Vorhersagen treffen zu können.
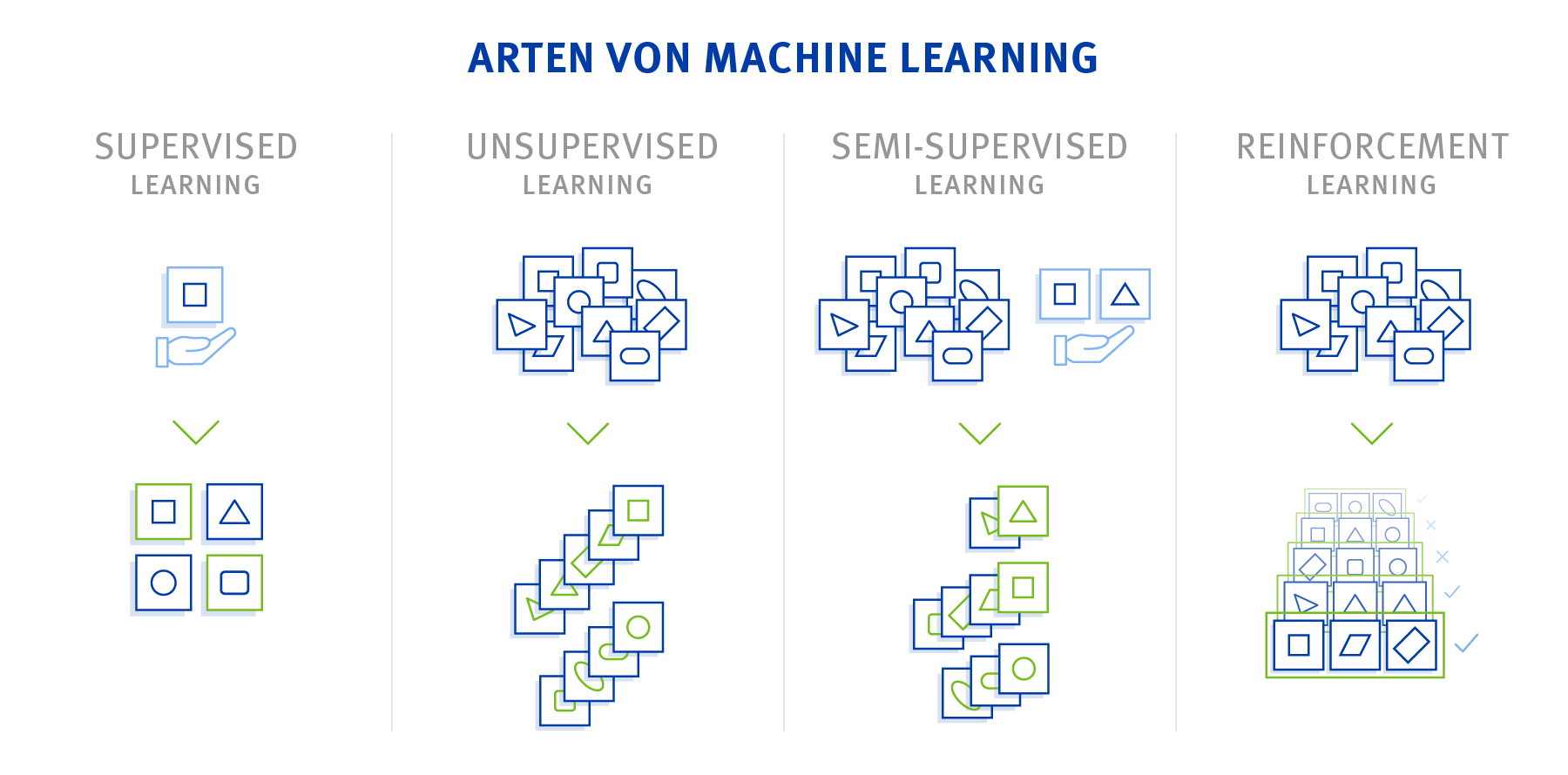
Nicht jeder Algorithmus funktioniert gleich. Grundsätzlich unterscheiden wir zwischen vier Arten: Supervised Learning, Unsupervised Learning, Semi-Supervised Learning, und Reinforcement Learning.
Supervised Learning (überwachtes Lernen)
Im „Supervised“ Fall ist das gewünschte Ergebnis des Machine-Learning-Algorithmus dem Entwickler schon bekannt. Das bedeutet, dass zum Lernen bereits valide Ergebnisse vorliegen. Der Algorithmus schaut sich die Ausgangsdaten an und versucht Muster zu erkennen, um auf die geplanten Ergebnisse zu kommen. Das erlernte „Wissen“ kann dann auf andere, unbekannte Ausgangsdaten angewandt werden. Ein Beispiel hierfür wäre ein Ordner mit Bildern von Haustieren. Der Programmierer sagt dem Algorithmus was ein Hund ist und was davon Nicht-Hunde sind. Mit diesen Informationen wird versucht, Muster zu erkennen (sog. Training). Gibt man dem Algorithmus dann ein neues Bild, wendet dieser die erlernten Muster an und kann somit Hunde von Nicht-Hunden unterscheiden.
Ein Vorteil vom überwachten Lernen ist, dass die Verfahren, aufgrund ihrer Strukturiertheit, gut nachvollziehbar sind. Dadurch ist die Interpretation der Daten leichter. Jedoch ist die Aufbereitung der Daten mit einem sehr hohen manuellen Aufwand verbunden.
Unsupervised Learning (unüberwachtes Lernen)
Der „Unsupervised“ Fall ist ergebnisoffen. Hier werden dem Algorithmus möglichst viele Daten gegeben und er versucht diese nach Gemeinsamkeiten zu gruppieren bzw. Anomalien herauszufinden. Dieser Ansatz ist z.B. bei Online-Shops beliebt, um Kunden mit ähnlichem Kaufverhalten zu gruppieren und entsprechende Produktvorschläge machen zu können.
Die Vorteile von diesem Algorithmus liegen in der teilweise vollautomatisierten Erstellung von Modellen. Das Modell lernt mit jedem Datensatz dazu und verfeinert gleichzeitig seine Berechnungen und Klassifizierungen. Dadurch ist ein manueller Eingriff nicht mehr notwendig.
Semi-supervised Learning (teilüberwachtes Lernen)
Das sogenannte teilüberwachte Lernen ist eine Mischung aus dem unüberwachten und überwachten Lernen. Grundsätzlich wird es für dieselben Anwendungsfälle wie die des Supervised Machine Learnings eingesetzt. Der Unterschied hier ist, dass nur ein kleiner Teil der Ergebnisse vorab bekannt ist und ein großer Bestand der Daten noch keine bekannte Zielvariable hat. Das hat den Vorteil, dass schon mit einer geringen Menge an bekannten Daten trainiert werden kann, da die manuelle Beschaffung von bekannten Beispieldaten sehr aufwendig und kostenintensiv ist. Anwendung findet das teilüberwachte Lernen beispielsweise in der Gesichtsidentifikation von Videoaufnahmen.
Reinforcement Learning (bestärkendes Lernen)
Bei dem bestärkenden Lernen erlernt das System selbständig eine Strategie. Welche Aktion in der jeweiligen Situation die richtige ist, wird dem System deshalb nicht vorgezeigt. Es wird durch eine Kostenfunktion oder ein Belohnungssystem bewertet. Durch positive oder negative Rückmeldung (Feedback) lernt das System so eine langfristig nutzenmaximierende Strategie auszuführen. Reinforcement Learning ist die Grundlage für Formen der künstlichen Intelligenz, die ohne menschliches Vorwissen komplexe Problemstellungen lösen können.
Der Vorteil hier ist, dass Reinforcement Learning sehr anpassungsfähig ist. Der Algorithmus kann sich neuen Umständen angleichen und sogar von anderen Maschinen lernen. Ein anderer Vorteil ist das automatisierte Lernen. Sollte das Ziel bekannt sein, die Lösung hingegen nicht, kann die Maschine diese oft, ohne menschliche Hilfe, finden. Bevor man sich für diese Art allerdings entscheidet, ist es wichtig zu beachten, dass dieser Algorithmus sehr viel Training erfordert. So können selbst relativ einfache Anwendungen Minuten, Stunden oder Tage dauern.
Machine Learning nutzen um interne Geschäftsprozesse zu verbessern
Mit Machine Learning kann man Zusammenhänge erkennen, die man als Mensch nicht so erkannt hätte. Viele Unternehmen setzen Machine Learning deshalb zur Verbesserung der internen Prozesse oder Workflows ein. Oft können durch diese Technologie Teile eines Prozesses automatisiert oder teilautomatisiert werden. Dadurch sinkt die Fehlerrate.
Chatbots beispielsweise sind schon sehr weit entwickelt. Sie können Kundenanfragen automatisiert beantworten und weiterleiten. Dabei bilden sie sich selbstständig weiter. Aber auch in der Personalabteilung eines Unternehmens findet Machine Learning Anwendung. So können Lebensläufe automatisiert abgeglichen werden. Machine Learning kann generell zur Analyse strukturierter oder unstrukturierter Kontextinformationen genutzt werden. Statt jeden Antrag von einem Mitarbeiter prüfen zu lassen, können Unternehmen Maschinen einsetzen, die in simplen Fällen eine Vorentscheidung treffen und eine Antwort vorformulieren.
Over- und Underfitting: Was ist das?
Ein bekanntes Anwendungsgebiet von Machine Learning ist die Bild- und Objekterkennung. Gerade hier taucht das Problem des Over- oder Underfitting häufig auf. Im Idealfall sollte das Modell, mit dem man den Algorithmus trainiert, genau zwischen Over- und Underfitting liegen. Das ist aber in der Praxis schwierig zu erreichen.
Ist das Modell, mit dem man trainiert, also zu komplex und speziell, tut sich ein Machine-Learning-Algorithmus schwer, allgemeingültige Muster zu erkennen. Das Ergebnis ist dann ein Algorithmus, der sehr gut mit den Trainingsdaten funktioniert und die gesuchten Objekte erkennt. Mit neuen Ausgangsdaten kann er aber wenig anfangen – das ist das sogenannte Overfitting.
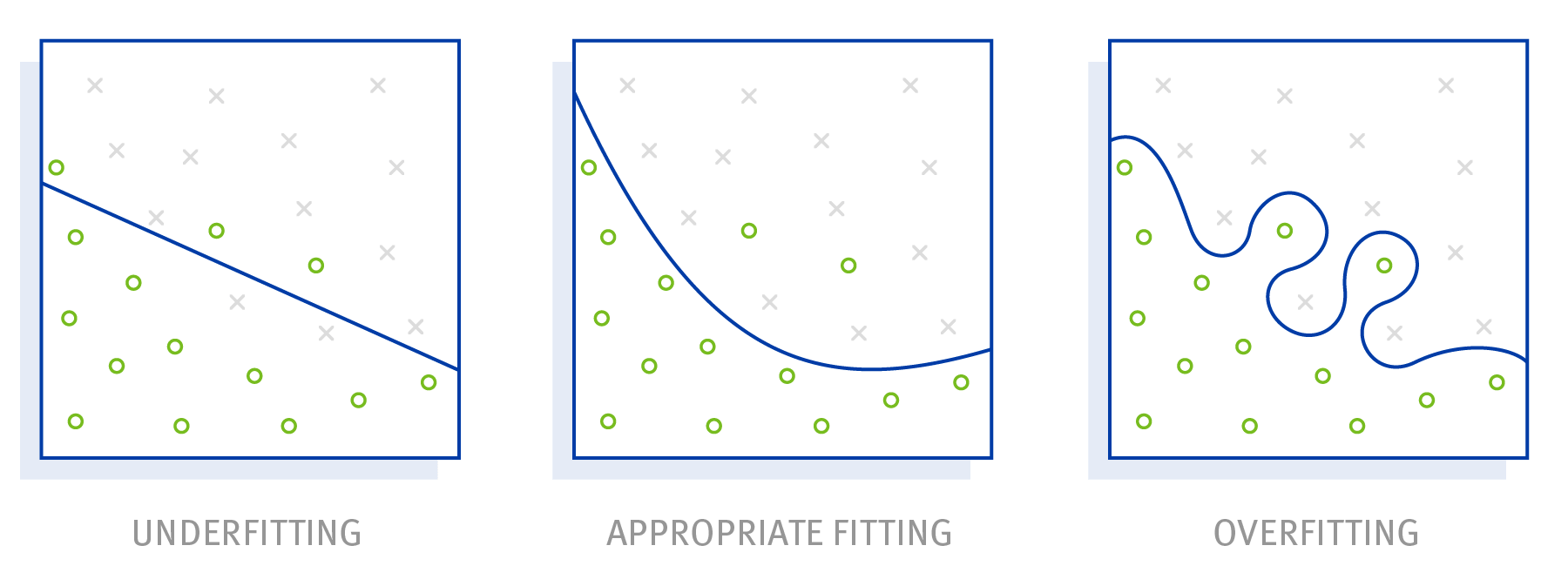
Umgekehrt kann es aber auch passieren, dass das Trainingsmodell zu einfach gehalten ist und die erkannten Muster zu allgemeingültig sind. Im Ergebnis erkennt der Algorithmus dann Objekte, wo gar keine sind. Überspitzt und vereinfacht ausgedrückt: Gras ist grün aber nicht alles, was Grün ist, ist auch Gras. Versucht man also nur anhand der Farbe Grün Gras zu erkennen, so hat man es mit sogenannten Underfitting zu tun.
Machine Learning und Datenschutz
Die Grundlage für erfolgreiche Machine-Learning-Algorithmen sind große und qualitativ hochwertige Datensätze, wobei es sich in den meisten Fällen um statische Muster handelt. Dennoch können auch sensible Daten bezogen werden und hier ist es wichtig diese zu schützen. Bei künstlicher Intelligenz und dem Teilbereich Machine Learning gestaltet sich das allerdings als Herausforderung, da es den eingesetzten Machine-Learning-Verfahren teilweise an Transparenz, Erklärbarkeit und Nachvollziehbarkeit der Ergebnisse mangelt. Man kann es mit Vorgängen im menschlichen Gehirn vergleichen, denn auch hier können wir nicht immer nachvollziehen, warum bestimmte Entscheidungen getroffen werden. Eine Antwort auf die Datenschutz-Problematik kann Crowd-Sourcing oder auch „differenzierter Datenschutz“ sein. Das bedeutet, dass in der Entwicklung anonymisierte Daten verwendet werden, die darüber hinaus mit einer Unschärfe versehen sind. Diese Datensätze lassen sich somit nicht auf eine Person zurückverfolgen. Viele Unternehmen garantieren aber auch, dass die Daten nur am Gerät selbst gespeichert werden und nicht an Dritte weitergegeben werden, beispielsweise bei der Funktion Gesichtserkennung. Es gibt viele mögliche „Antworten“. Wichtigste Instanz bei der Verarbeitung von personenbezogenen Daten ist die Rechtsvorschrift der DSGVO. Sollte man also ein Machine-Learning- oder KI-Projekt umsetzen wollen, empfiehlt es sich einen Datenschutzexperten zu konsultieren und gegebenenfalls auch ins Projektteam einzubinden.
Machine Learning ist mehr als ein Hype und berechtigt auf Platz drei der wichtigsten IT Themen. Wie es mit der Technologie in den nächsten Jahren weiter geht, wissen wir noch nicht. Transparenz wird aber auch hier ein wichtiges Thema bleiben, nicht nur in Bezug auf den Datenschutz. Menschen wollen verstehen können: Wer hat diese Entscheidung getroffen, Mensch oder Maschine? Hier müssen wir uns mit der Frage auseinandersetzen: Ist vollständige Transparenz überhaupt möglich?
Solltest du dich, ob Unternehmer oder Privatperson, für Machine Learning interessieren, ist es wichtig, Geduld zu haben. Machine Learning ist komplex und nimmt viel Zeit in Anspruch. Trotzdem lohnt es sich, denn die Technologie ist, wenn sie richtig eingesetzt wird, eine Technologie, in der noch viel Potenzial steckt.
Falls du eine eigene Machine Learning Lösung für dein Unternehmen entwickeln willst und auf der Suche nach einem Partner bist, schau gerne hier vorbei. Unsere Kolleginnen und Kollegen beraten dich gerne unverbindlich zum Thema.