Machine Learning for beginners
Everyone is talking about machine learning. The interest in this technology has increased by almost half in the last three years at Google Trends and is even ranked third among the most important IT topics. This also has an impact on finances: In Germany, €220.6 billion in sales were generated directly or indirectly by machine learning in 2019. And more than half of all German companies use at least one ML application.
Following such trend can be tough with getting lose sight of the basics. This is where we want to help and give some insights: What is machine learning, how does it work, what types of algorithms are available and about what should be looked at when it comes to data protection? We want to spare you the long search on the internet and explain the basic features of machine learning to non-technical people or beginners:
What is machine learning and how does this part of AI work?
Machine learning is, as you can see in the title, a subarea of artificial intelligence and means the acquisition of new knowledge by an artificial system. In short terms, the computer generates knowledge from experience and independently finds solutions for new or already known problems.
The functionality of machine learning is based on human learning. The developer is the “teacher” and trains the algorithm. Through training and example data, the algorithm can recognize patterns and correlations and thus learn from data. The goal of machine learning is to intelligently connect data, find connections, draw conclusions and make predictions.
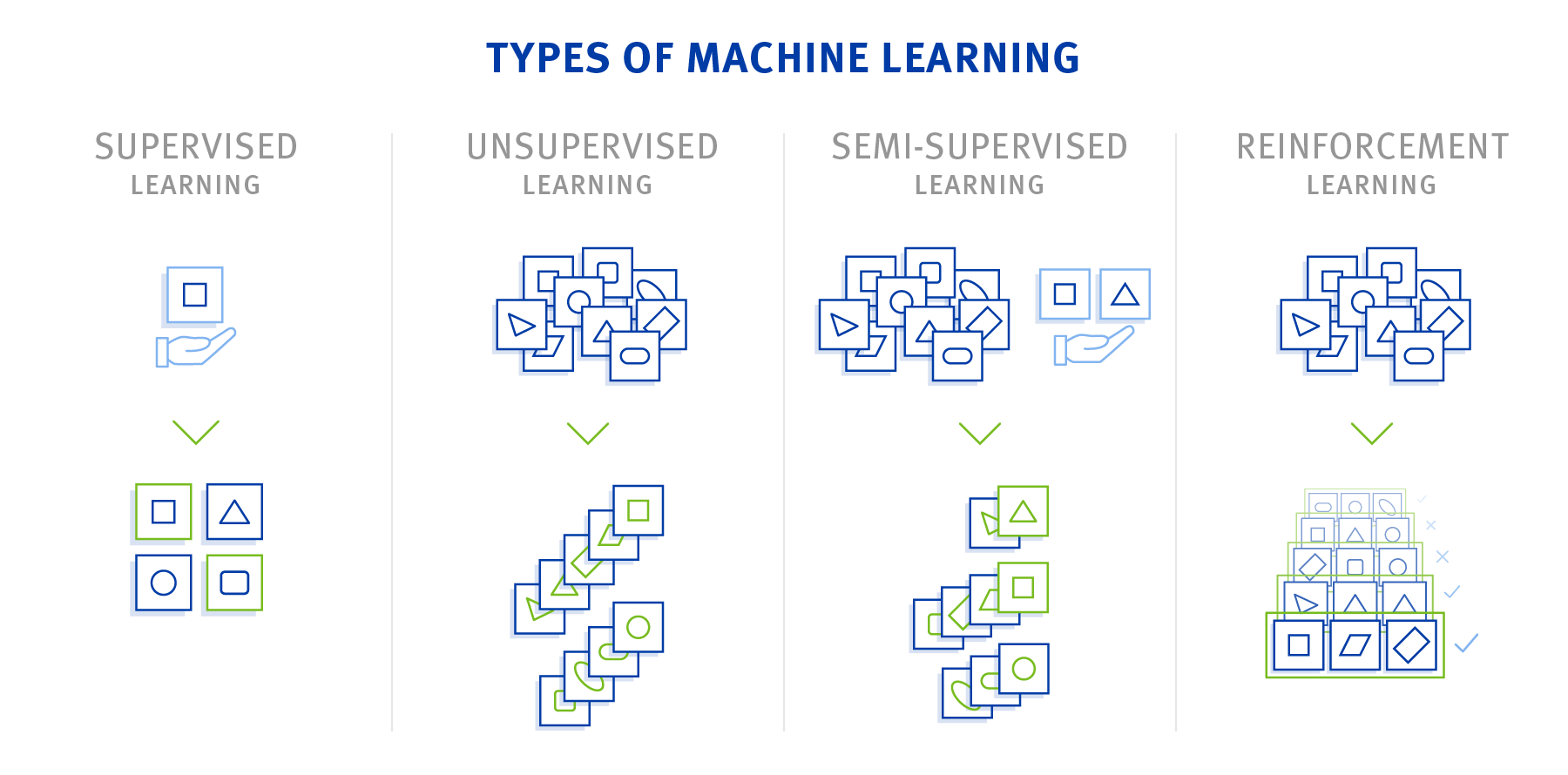
Not every algorithm works the same way. Basically, we distinguish between four types: supervised learning, unsupervised learning, semi-supervised learning and reinforcement learning.
Supervised Learning
In the “supervised” case the desired result of the machine learning algorithm is already known to the developer. This means that valid results are already available for learning. The algorithm looks at the initial data and tries to recognize patterns in order to get to the planned results. The learned “knowledge” can be applied to other, unknown output data. An example would be a file with pictures of pets. The programmer tells the algorithm which picture shows a dog and which shows something else. This information is used to try to recognize patterns. If you give the algorithm a new image, it applies the learned patterns and can thus distinguish dogs from non-dogs.
An advantage of supervised learning is that the procedures are easy to understand due to their structure. This makes it easier to interpret the data. However, the preparation of the data needs a very high manual effort.
Unsupervised Learning
The “unsupervised” case is open-ended. Here the algorithm receives as much data as possible and tries to group them according to similarities or to find out anomalies. This approach is popular with online shops, for example, in order to group customers with similar purchasing behavior and to be able to make corresponding product suggestions.
The advantage of this algorithm is the almost fully automated creation of models. The model learns with each data set and at the same time refines its calculations and classifications. Thus, manual intervention is no longer necessary.
Semi-Supervised Learning
The semi-supervised learning is a mixture of unsupervised and supervised learning. Basically, it is used for the same applications as supervised machine learning. The difference here is that only a small part of the results is known in advance and a large stock of data doesn’t have a known target variable yet. This has the advantage that training can already be done with a small amount of known data, since the manual acquisition of known example data is very complex and cost-intensive. Semi-supervised learning is used, for example, in the face identification of video recordings.
Reinforcement Learning
With reinforcement learning, the system independently learns a strategy. In this case the system doesn’t know which action is the right one in the respective situation. It is evaluated by a cost function or a reward system. Through positive or negative feedback, the system learns to execute a strategy that maximizes long-term benefits. Reinforcement learning is the basis for forms of artificial intelligence that can solve complex problems without prior human knowledge.
The advantage is that reinforcement learning is very adaptable. The algorithm can adapt to new circumstances and even learn from other machines. Another advantage is automated learning. If the goal is known but the solution isn’t, the machine can often find it without the help of human. However, before deciding to use this method, it is important to note that this algorithm requires a lot of training. Even relatively simple applications can take minutes, hours or days.
Use machine learning to improve internal processes
With machine learning you can recognize connections that you wouldn’t have been recognized by a human being. Many companies therefore use machine learning to improve internal processes or workflows. Often parts of a process can be fully or partially automated by this technology. This reduces the error rate.
Chatbots, for example, are already very well developed. They can answer and forward customer requests automatically. In doing so, they educate themselves further independently. But machine learning can e.g. also be used in the Human Resources department of a company. CVs can be compared automatically. Machine learning can generally be used to analyze structured or unstructured context information. Instead of having every request checked by an employee, companies can use machines that make a preliminary decision in simple cases and pre-formulate a response.
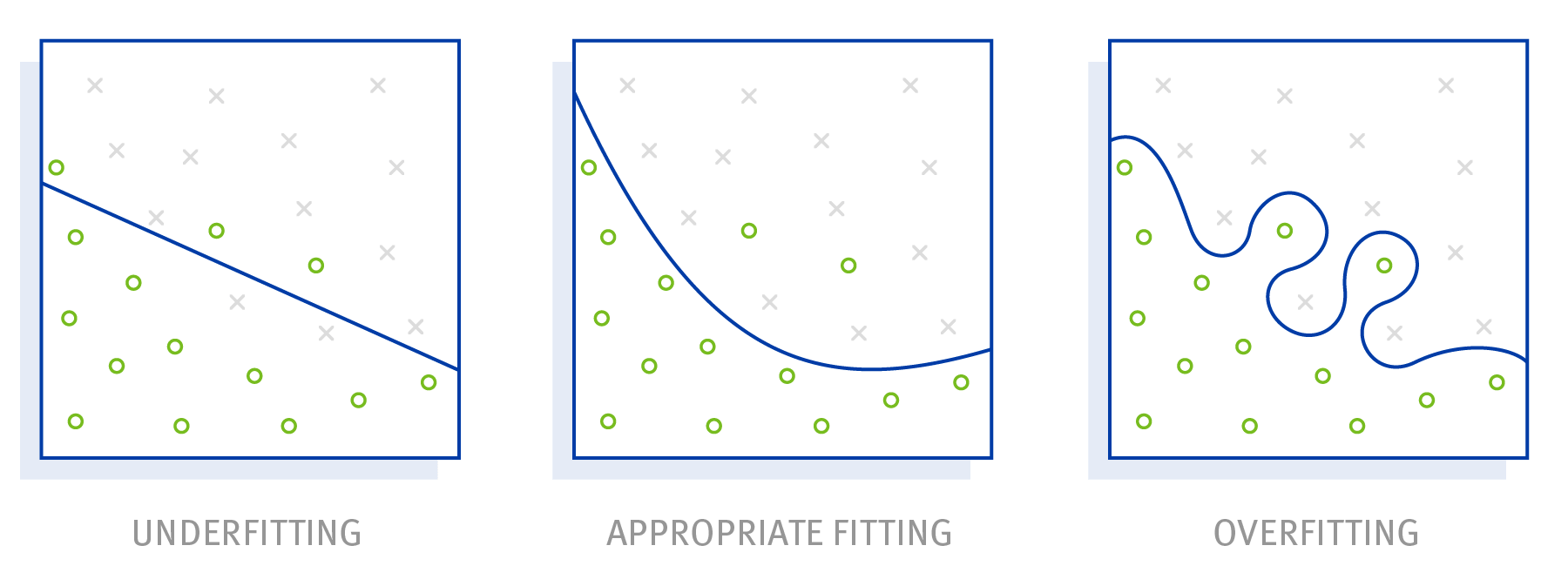
Over- and Underfitting: What is that?
A well-known application area of machine learning is image and object recognition. Especially here, the problem of over- or underfitting often arises. Ideally, the model who you train the algorithm with, should lie exactly between over- and underfitting. But this is difficult to achieve in practice.
So, if the model you train with is too complex and special, a machine learning algorithm will have a hard time recognizing universally valid patterns. The result is then an algorithm that works very well with the training data and recognizes the objects you are looking for. However, it can do less with new output data – this is called overfitting.
On the other side, it can also happen that the training model is kept too simple and the recognized patterns are too general. As a result, the algorithm recognizes objects where there are none. To put it simply: grass is green but not everything that is green is also grass. So, if you try to recognize grass only by the color green, you are dealing with so-called underfitting.
Machine Learning and Data Protection
The basis for successful machine learning algorithms are large and high-quality data sets, which in most cases are static patterns. Nevertheless, sensitive data can also be obtained and this is followed be the important need to protect them. With artificial intelligence and the subarea machine learning, this turns out to be a challenge because the machine learning methods sometimes lack transparency, traceability or the ability to explain the results. It can be compared with processes in the human brain: there also can’t always understand why certain decisions are made. One answer to the data protection problem can be crowd sourcing. This means that anonymous data is used in development, which is also furnished with fuzziness. These data records can therefore not be traced back to a person. However, many companies also guarantee that the data is only stored on the device itself using it and is not passed on to third parties, for example in the face recognition function of a smart phone. There are many possible “answers”. The most important instance in the processing of personal data are the legal guidelines of the GDPR. So, if you want to implement a machine learning or AI project, it is advisable to consult a data protection expert and, if necessary, to add him or her as member to the project team.
Machine learning is more than just a hype and justifies the third place of the most important IT topics. We don’t yet know how the technology will develop in the next few years, but transparency will remain an important issue, not only in terms of data protection. People want to be able to understand: Who made this decision, human or machine? This is where we have to deal with the question: Is full transparency ever possible?
If you, whether an entrepreneur or a private person, are interested in machine learning, it is important to have patience. Machine learning is complex and takes a lot of time. Nevertheless, it is worth it, because the technology, if used correctly, still has a lot of potential.
If you want to develop your own machine learning solution for your company and you are looking for a partner, click here. Our colleagues will be happy to advise you on your project without obligation.