Summarizing Video Conferences With the Help of Artificial Intelligence
In times of the coronavirus, video conferencing has become a huge popularity. The trend is to increasingly rely on online meetings in the future. But how can it be ensured that absent people receive all relevant information? One option would be to take meeting notes. Depending on the author, these notes could be incomplete and relevant information could be forgotten.
Recording a session would be a more reliable method. Many video conferencing tools now offer this function so that absent participants can view the missed session afterwards. In practice, it has been shown that it is very difficult to actively follow a recorded session.
Using artificial intelligence, it is possible to shorten recorded conferences in a meaningful and compact way. Harald Nezbeda, one of our employees, attempted to build such a system from open source components for his final thesis as part of the university course in data and AI management at the University of Klagenfurt.

Application
Whisper from OpenAI is used for speech recognition. This tool needs to be supplemented in some places, for example to identify speakers and recognize pauses in conversations.
The process is structured in different steps:
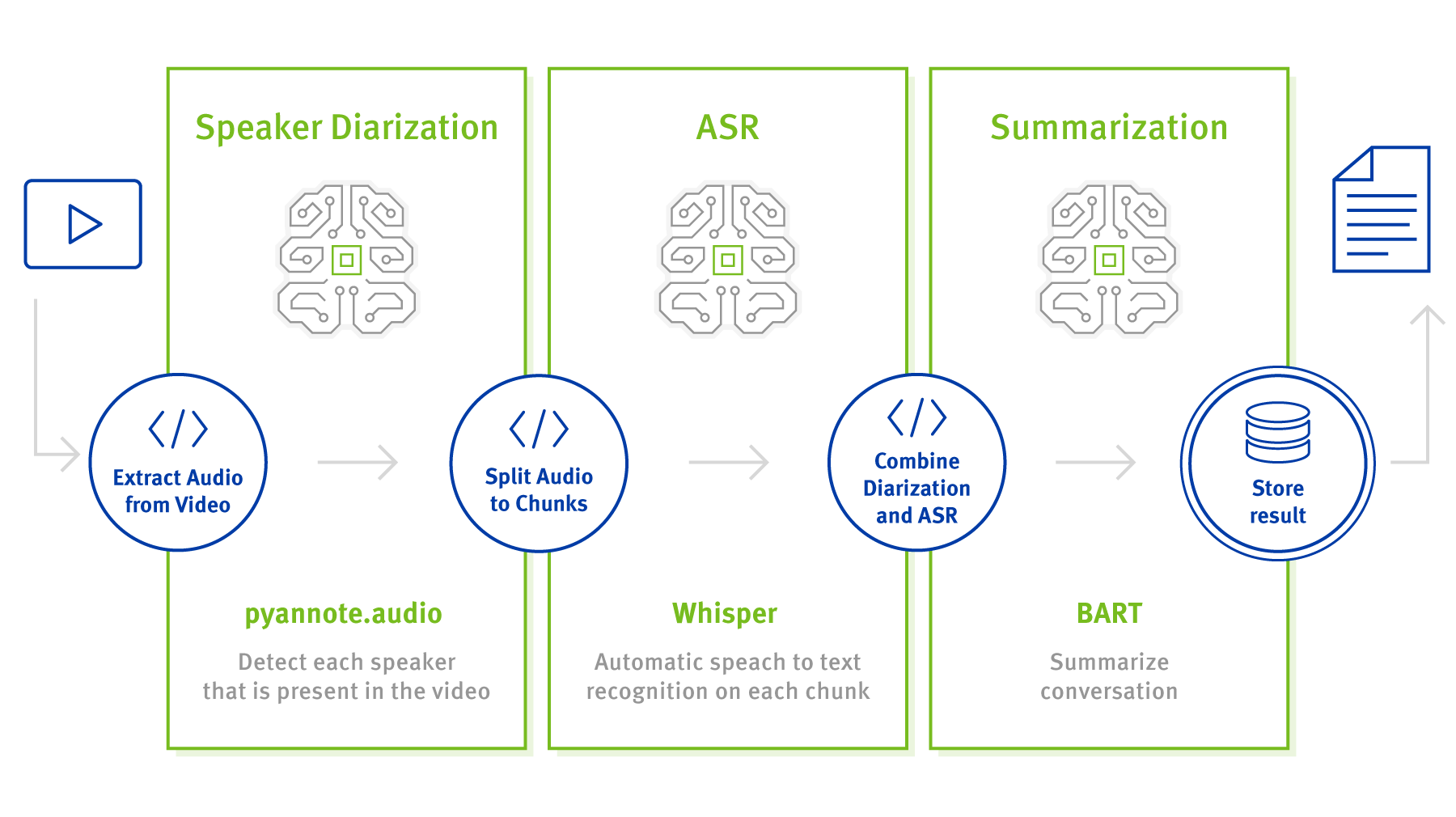
- Extract audio from video
An audio file is extracted from a video. The image material is no longer required for further processing. - Speaker diarization
In this step, all speakers in the video are recognized and an RTTM file is created using the pyannote.audio tool. - Share audio parts from speakers
The generated RTTM file is divided into different audio blocks in this step. - Speech recognition – ASR (Automatic Speech Recognition)
With Whisper, the audio blocks are automatically recognized as text, transcribed and stored as TXT files. - Merging ASR and Speaker Diarization
The RTTM file from step 2 and the TXT file from step 4 are merged using a Python function. The following formats are generated:
TXT format
The text is displayed as a dialog.{SPEAKER}: {ASR_TEXT}SPEAKER stands for the speaker defined in the RTTM file and ASR_TEXT for the transcribed text.
JSON format
The JSON output contains more details and can be used later for troubleshooting. The schema here is as follows:{ "$schema": "https://json-schema.org/draft/2020-12/schema", "type": "array", "items": { "type": "object", "properties": { "start": { "type": "number" }, "duration": { "type": "number" }, "speaker": { "type": "string" }, "text": { "type": "string" } }, "required": [ "start", "duration", "speaker", "text" ] } } - Merging
The BART model is used to combine the TXT and JSON format and create a summary of the entire conversation. It has also been shown that the SAMSum data set can be used efficiently for fine-tuning BART. Due to the existing models and data, the summary is currently only possible in English.
Conclusion
It can therefore be said that artificial intelligence can make a significant contribution to summarizing video conferences. With the help of ASR and speaker diarization, it is possible to present the content of a video conference in text form and shorten it to a compact and content-relevant form using the BART model.
Since the work was written some time ago, it is quite possible that the model described above no longer works optimally due to changes in the open source applications.
The project is available on Github.
RELATED TOPICS
What is Artificial Intelligence? →
Anexia Artificial Intelligence Development →